Optimal Chunk-Size for Large Document Summarization
Mingtian
Ray
1. Introduction
Large Language Model (LLM) is good at text summarization. However, the limited context window of LLM poses a challenge when summarizing large documents. We discuss a limitation of the commonly used summarization strategy and introduce a straightforward improvement.
2. The Common Strategy of Large Document Summarization
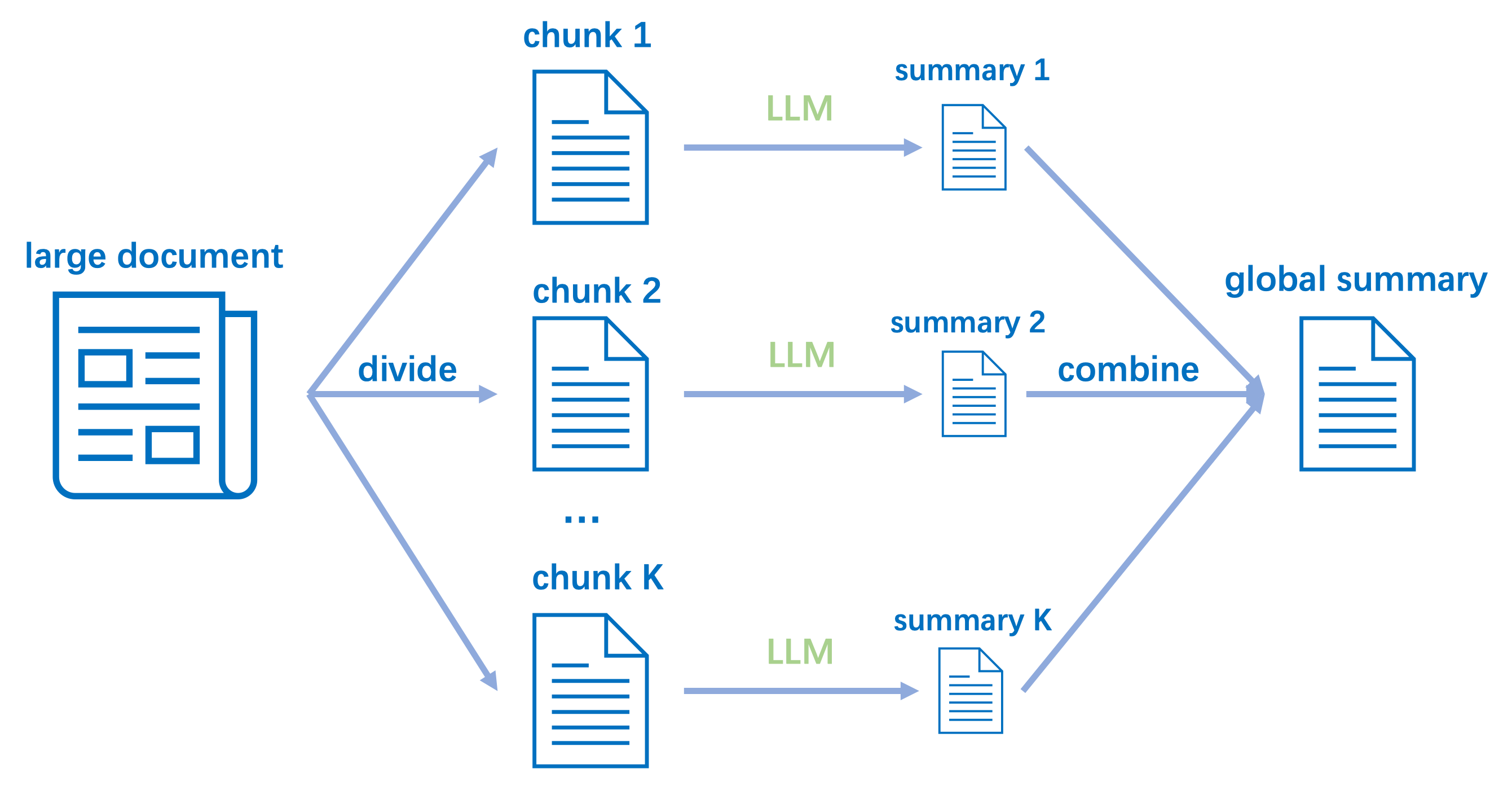
The common strategy for summarizing large documents involves the following steps:
Determine a based on the LLM context window and the prompt size.
Divide the document into chunks, where the first chunks each have a size of and the last chunk has a size
where
We use to represent the smallest integer that is equal or greater than x, e.g. .
Summarize the chunks independently using LLM.
Combine the chunk summaries into one global summary of the document using LLM.
The subsequent figure illustrates this general summarization strategy. The implementation of this strategy can be found in common LLM libraries like LangChain or LlamaIndex.
3. Problem: Biased Global Summary Due to Poor Chunk Size Selection
When applying the same across all documents, there's a risk that the last chunk in some documents could be significantly smaller than the preceding chunks in the same document.
Example 1: For a document of size 11 and a chosen , the resulting chunk sizes would be .
This disparity can lead to the following problem:
In the combination stage, the summary of the final chunk could be erroneously weighted as equally important as the others, thereby introducing a bias in the global summary of the original document.
See our Jupyter Notebook for a practical example of how this problem occurs in large document summarization.
Intuitively, we want all chunks to have roughly the same amount of information, so the equally weighted combination in the final step will not introduce any bias to the global summary. We can further simplify this requirement by assuming that chunks of comparable sizes contain roughly the same amount of information. Therefore, our goal is to ensure that all chunks are of similar size.
To measure the "similarity" of the chunk sizes, we can calculate the maximum size difference between the longest chunk and the shortest chunk within the same document. For example, for the summary strategy described in Section 2, the worst case scenario is when , so the last chunk has the smallest size of 1 and
This disparity can be substantial for larger values of . While intuitively reducing the can diminish this gap, it simultaneously increases the value of , which in turn elevates the cost of the LLM. We then discuss how to reduce the chunk difference gap with a minimum chunk number .
4. Optimal Automatic Chunk Size Determination
Firstly, we decide a based on the LLM context window and the prompt size, so the minimum chunk number is
We then calculate the 'average' integer chunk size
which is used to divide the document into chunks: the first chunks are of size and the last chunk has size
As shown in the following example, this simple trick has already improved the common strategy.
Example 2: Given and . We derive and . The document is then divided into three chunks of sizes , a noticeable improvement over the prior method which resulted in sizes .
However, this method is still not optimal in some cases.
Example 3: Given and . We derive and . This divides the document into three chunks of sizes , which is worse than an obvious division of .
To further reduce the gap between the and , we can incrementally transfer one token from the preceding chunks to the last chunk until it reaches the size of . In total, we need to move tokens where
As a result, chunks now have the size , while the remaining chunks maintain their original size of .
The illustration below demonstrates how, by redistributing a token from one preceding chunk to the last chunk in Example 3, we achieve a more balanced chunk size list .

In this approach, we only encounter two potential chunk sizes: and . Consequently, the between chunks is just a constant of 1 even in the worst case. Thus, this strategy is optimal in practice while maintaining the smallest possible number of chunks.
5. Implementation
We provide a basic implementation below.
Visit our Github Repo for hands-on examples and practical comparisons!
import tiktoken
import math
def auto_chunker(document, max_chunk_size, model):
tokenizer = tiktoken.encoding_for_model(model)
document_tokens = tokenizer.encode(document)
document_size = len(document_tokens)
# total chunk number
K = math.ceil(document_size / max_chunk_size)
# average integer chunk size
average_chunk_size = math.ceil(document_size / K)
# number of chunks with average_chunk_size - 1
shorter_chunk_number = K * average_chunk_size - document_size
# number of chunks with average_chunk_size
standard_chunk_number = K - shorter_chunk_number
chunks = []
chunk_start = 0
for i in range(0, K):
if i < standard_chunk_number:
chunk_end = chunk_start + average_chunk_size
else:
chunk_end = chunk_start + average_chunk_size - 1
chunk = document_tokens[chunk_start:chunk_end]
chunks.append(tokenizer.decode(chunk))
chunk_start = chunk_end
assert chunk_start == document_size
return chunks
In practice, an improved chunking strategy should also consider the boundaries of sentences or paragraphs. We will discuss how to integrate this consideration into this method in our upcoming blog post. Subscribe below to stay updated and ensure you never miss enhancements for your AI product!
6. Want to Improve the Chunking for Your Domain-specific Documents?
In this blog post, we propose an optimal chunking strategy under the assumption that chunks of similar sizes hold comparable amounts of information. This proposed method could also benefit other LLM tasks, such as retrieval-augmented question answering. In real-world situations, this assumption might not apply to domain-specific documents. For instance, in certain scientific papers, references at the end may not necessarily reflect the document's core semantics.