How to Evaluate and Select Embedding Models?
Mingtian
Ray
Which Embedding Model To Use?
The performance of RAG heavily relies on the quality of the embedding model. The embedding models available nowadays are usually pre-trained and evaluated on a general corpus. Therefore, the rankings of embedding models on the Hugging Face MTEB leaderboard may not reflect their true performance for domain-specific applications. Many developers find that the top-ranked embedding models on the leaderboard sometimes perform worse than those lower-ranked models in specific domains like finance, law, or medical records.
Therefore, it is extremely important to choose the best embedding model for your data and application to improve the accuracy of your AI applications. We introduce the Embedding Model Evaluation service, as part of Vectify AI's RAG platform, which provides a systematic and hassle-free way to evaluate and select the best embedding model for your data and applications.
What Evaluation Metric Matters in the RAG Applications?
There are many evaluation metrics in the information retrieval literature. However, which metric is most relevant to RAG performance? In common RAG use cases, we primarily care about whether the correct passage appears in the retrieved list, which can be accurately reflected by the recall rate. Given a query, the top-K recall rate (we denote as Recall@K) is defined as
Intuitively, recall measures the proportion of relevant documents that are successfully retrieved, providing a clear metric to compare the effectiveness of different embedding models on your data.
To calculate the recall rate, we need to know the ground truth passage for each test query. However, preparing the test query-passage pair requires significant labeling effort. We then introduce our evaluation data generation strategy, which enables automatic evaluation with just one click.
Preparing Evaluation Data in One Click
In our evaluation system, we use powerful LLMs, such as ChatGPT-4, to generate hypothetical queries that simulate real-world queries for each passage. The generated queries thus align with the content of the passage, providing us with ground-truth test query-passage pairs.
In addition to the LLM-generated evaluation data, our evaluation system also allows users to customize their evaluation dataset and continuously improve the evaluation based on their use cases. Please contact us for access to the closed beta version of this function.
A Journey of Automatic Embedding Model Evaluation and Selection
Let's go through each component of the evaluation system.
1. Generate Evaluation Data
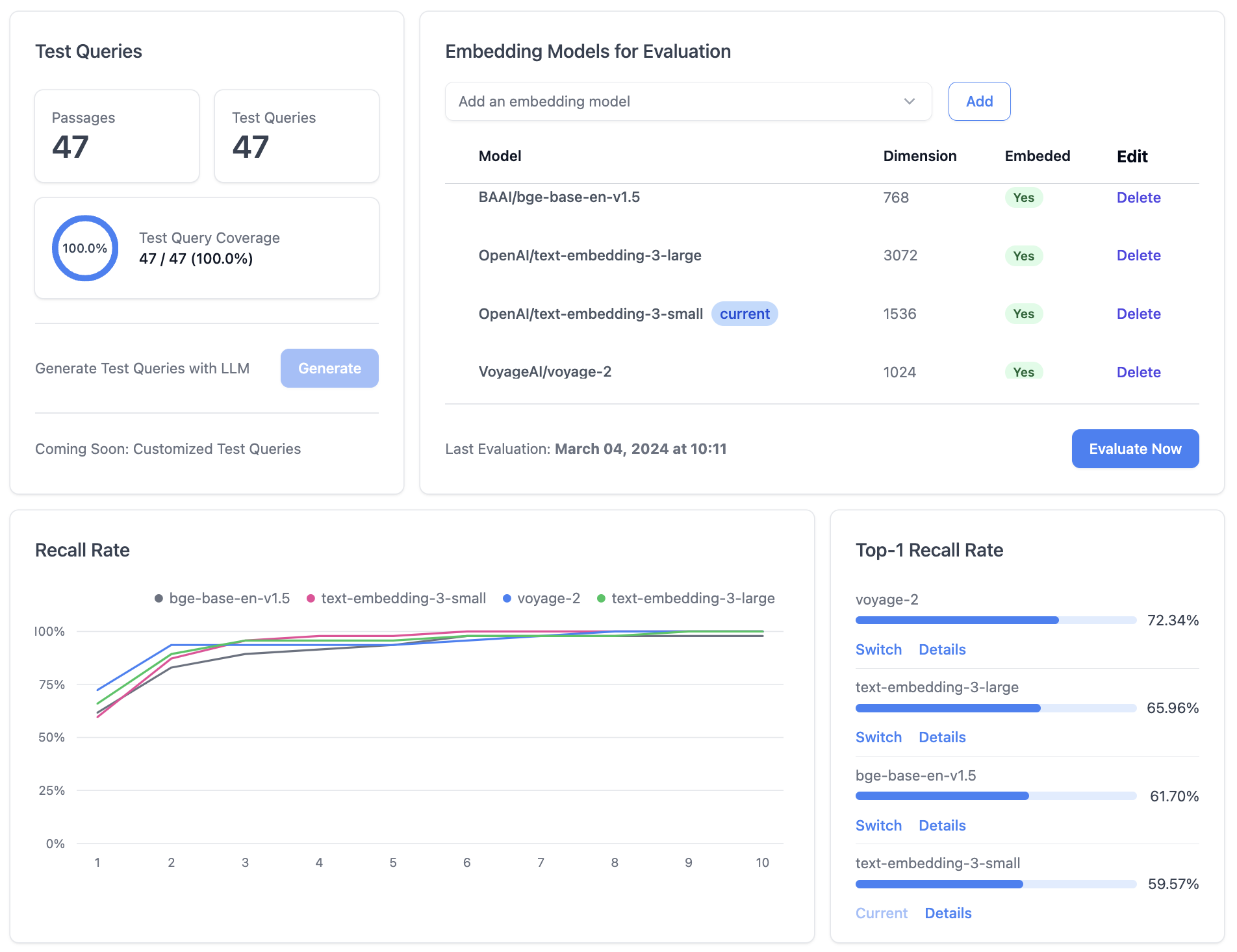
In our evaluation system, simply click on the "Generate" button under the "Test Queries" panel to automatically generate test queries for your data source. You could also view characteristics of the test queries, such as query number and test coverage of all the passages in the data source.

2. Select Embedding Model
Once the test queries are prepared, you can proceed to select the embedding models you wish to evaluate, under the "Embedding Models" panel. Choose and add the embedding models that you are interested in, where you can see the details of each embedding model, such as model name, dimension and embedding status.
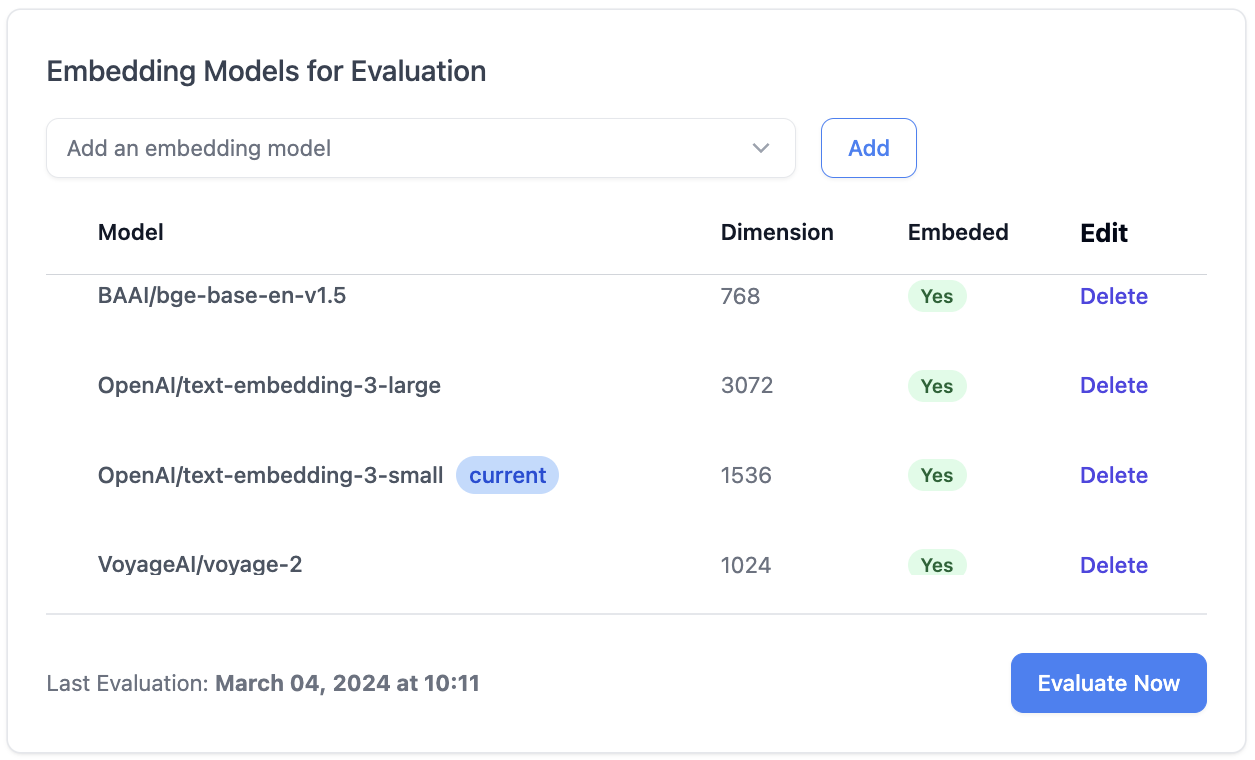
The next step is to embed the documents in your data source using the selected embedding models. We make sure that the embeddings under different models are always correct and up-to-date. You can see in real-time the embedding status (ready or not) of the data source for each embedding model in the "Embedding Models" panel.
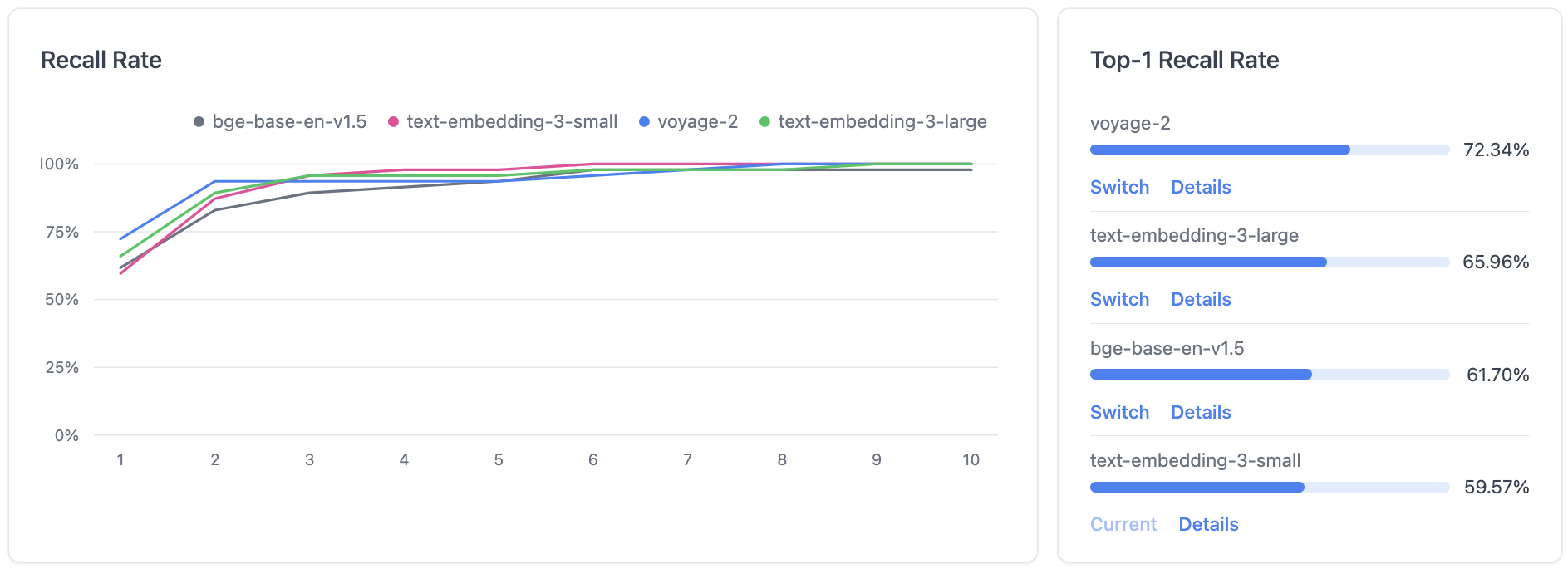
3. Top-K Recall Rate Curve
The plots of Recall@K with different retrieval numbers K (x-axis) are displayed in the "Recall Rate" panel. You can further click on the retrieval number to see a performance ranking for the embedding models.
4. Review Incorrectly Retrieved Queries
An important part of the evaluation process is to review the queries that were incorrectly retrieved by each embedding model. This analysis can provide insights into the types of errors each model might have. Understanding these limitations can help you choose an embedding model that aligns with your application and data characteristics.

5. Embedding Model Selection
You can simply click on the "Switch" button to select the embedding model that offers the best performance for your data. Your retrieval API will automatically switch to this embedding model.

Conclusion
Evaluating embedding models doesn't have to be a complex and time-consuming process. With Vectify AI's Evaluation-as-a-Service (EaaS) for embedding models, you can easily evaluate and select the best embedding model for your data and RAG pipelines, ensuring that your applications are powered by the most effective embedding models available. Visit our platform and start evaluation today.