Multi-Strategy Retrieval Agent
Mingtian
Ray
Introduction
Retrieval Augmented Generation (RAG) is a prominent framework that bridges Large Language Models (LLMs) with external knowledge bases. Building a RAG pipeline typically involves the following steps:
- First convert the external knowledge passages into vector embeddings using a pre-trained embedding model.
- When a query is posed, convert the query into a vector form using the same embedding model.
- Use the K-nearest neighbor (KNN) search to retrieve the top-K knowledge passages with the highest embedding similarity to the query.
- Supply the query with the retrieved passages as contextual information and send it to the LLM to generate the response.
Limitation of Traditional Embedding-based Retrieval
The traditional embedding-based retrieval methods are based on the assumption that semantically similar texts are closely located in the vector space. However, this approach encounters several notable challenges:
- Multi-Modal Semantics: For queries encompassing multiple objectives or diverse semantic concepts, a singular embedding may inadequately capture the full semantic spectrum.
- Model-Query Misalignment: The embedding models are typically pre-trained on standard text corpora rather than query-answer pairs. This can lead to suboptimal alignment of query embeddings within the desired semantic space.
- Approximate Search Limitations: The K-nearest neighbor search, being an approximate method, struggles with precise conditions, such as "information post-2023".
This blog post introduces how our retrieval agent can resolve the first two challenges. Check out our Metadata Agent blog post for the discussion about how to tackle the third challenge.
Vectify's Multi-Strategy Retrieval Agent
Vectify's retrieval agent utilizes the assistance of Large Language Models (LLMs) to tackle the first two challenges.
Query Decomposition: For a complex query, we employ LLMs to break it down into sub-queries that encapsulate different semantic aspects. Each sub-query can then be individually searched in the vector database.
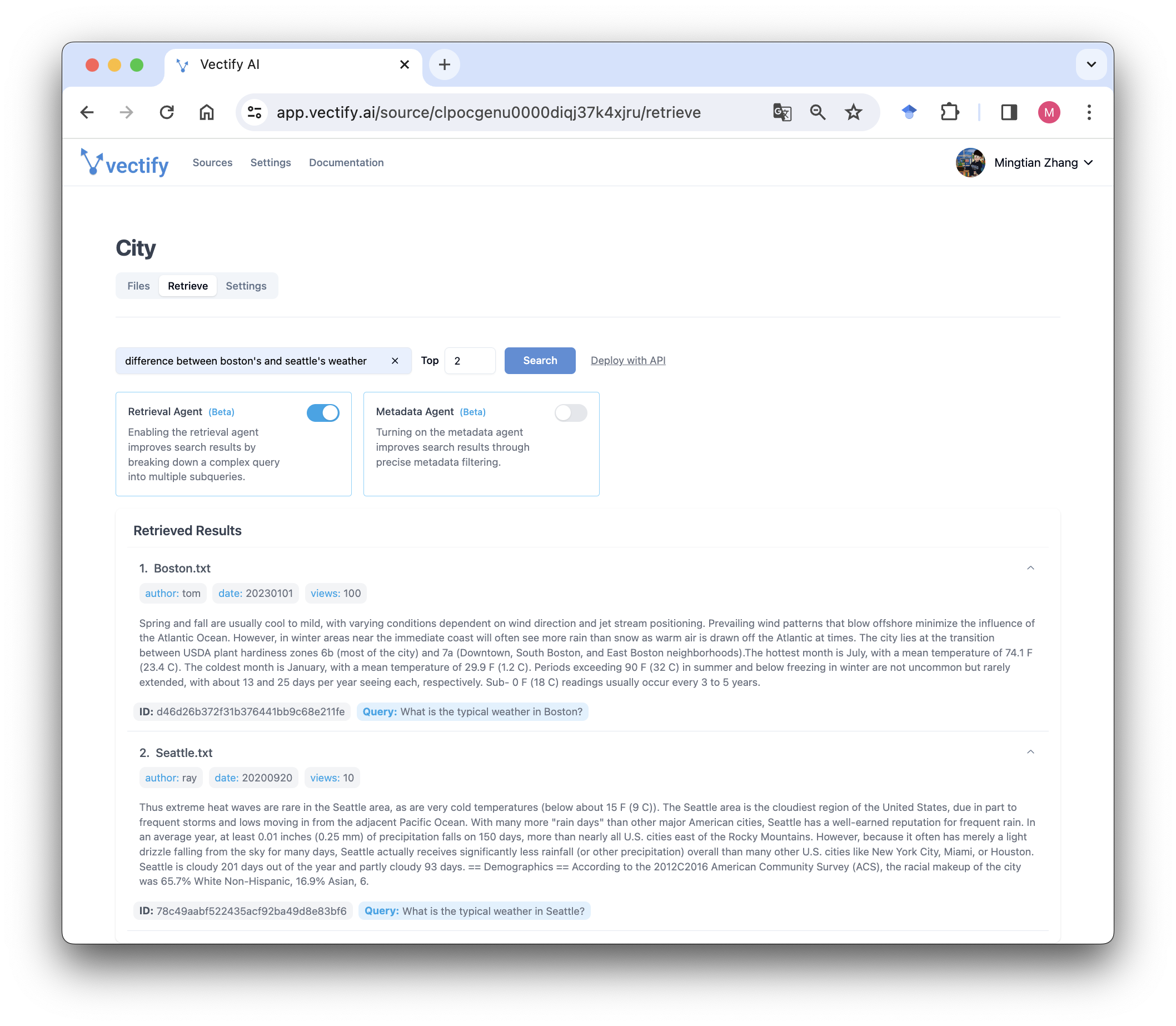
Example: What is the weather difference between Boston and Seattle?
Query Decomposition:- What is the weather in Boston?
- What is the weather in Seattle?
Hypothetical Answer Generation: To better align queries with pre-trained embedding models, LLMs can be used to generate hypothetical answers that more closely match the expected answers in the vector database. This approach is also referred to as Hypothetical Document Embedding (HyDe).
Example: What is the weather in Boston?
Hypothetical Answer: Summers in Boston are warm and humid, while winters are cold and snowy.
Vectify's retrieval agent employs these two strategies to generate multiple synthetic queries and hypothetical answers based on the user's original query. These synthetic queries are then combined with the original user's query to conduct semantic searches in the Vector Database.
Efficient Re-rank and Merge
The strategies outlined previously introduce a significant challenge: managing the retrieval results from multiple queries. Consider a scenario where N synthetic queries are generated based on the user's query, and each yields a top-K list of retrieved items. This results maximum number of retrieval items, potentially consuming a substantial number of tokens. Practically, users often seek a singular, consolidated list of retrievals, with the list's size dynamically adjusted based on their token usage. Thus, an efficient approach involves merging these various retrieval lists into a single list while preserving the ranking information.
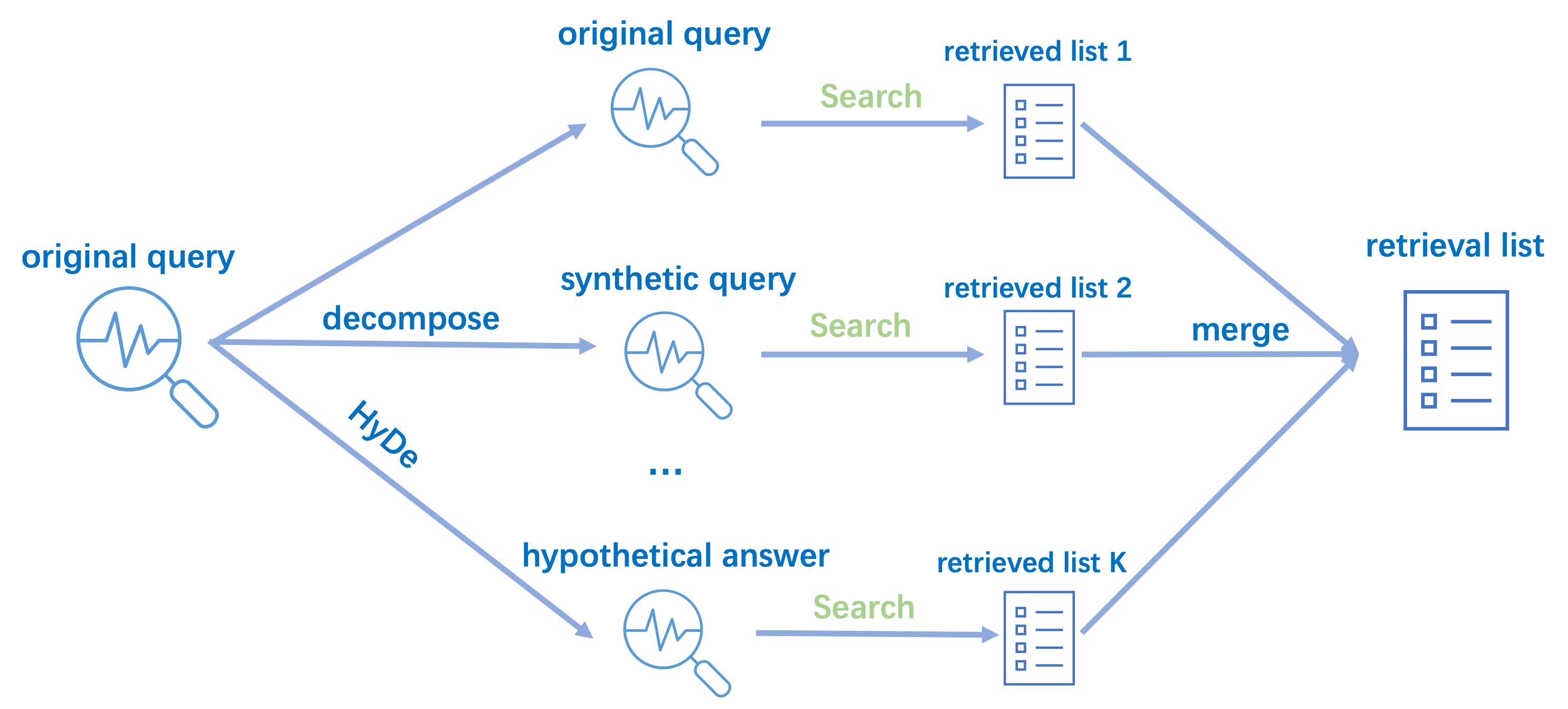
Vectify's retrieval agent can efficiently re-rank and merge the retrieved items from multiple retrieval lists, our technique not only optimizes for relevance but also for diversity, ensuring that the final list of retrieved items is not just accurate but also comprehensive and representative of the various facets of the query even with a small top-K setting. The above figure shows the retrieval process of our Multi-Strategy Retrieval Agent.
Use the Multi-Strategy Retrieval Agent
The Metadata Agent has been integrated in our RAG platform. Simply upload your documents in Vectify's Dashboard and our Multi-Strategy Retrieval agent becomes available instantly for your data.
You can also integrate our retrieval agents into your product using our SDK.
# pip install vectifyai
client = vectifyai.Client(api_key='YOUR_API_KEY')
results = client.retrieve(
query = 'What are the latest climate change policies in European countries after 2020?',
top_k = 5,
sources = ['docs'],
agent = 'on'
)
Try it out
We invite you to try out our Multi-Strategy Retrieval Agent. Start today for free and unlock the potential of RAG with hassle-free retrieval and intelligent agents from Vectify AI.