Introducing Vectify's RAG Platform
Mingtian
Ray
Introduction
Retrieval Augmented Generation (RAG) has gained significant popularity, especially in the context of Large Language Model (LLM) applications. It serves as a bridge between proprietary data and the power of LLM, enhancing the way we interact with complex information.
To build the retrieval engine in your RAG applications, it usually takes the following steps:
- Pre-process the documents into chunks
- Transform all the chunks into vector embeddings using an embedding model and save them into a vector database.
- Transform the query into vector embedding using the same embedding model and conduct search in the vector database.
We announce the Vectify's RAG Platform, which provides a hassle-free integrated solution for the above complicated process, with better accuracy and efficiency.
Hassle-free RAG Service: Retrieval Data Management and API
Our platform offers an intuitive interface for managing your data sources and uploading documents with ease. Upon uploading, we take care of the entire data embedding process and maintain a hosted vector database for you. You have the flexibility to select from a variety of embedding models, including OpenAI's advanced text-embedding-ada-002, as well as other popular pre-trained models available on our server. After processing your documents, a production-ready retrieval service becomes accessible through both our API and Python SDK, streamlining your data handling experience.
Improve RAG Performance: Advanced Retrieval Agents
In addition to the classic semantic search, our RAG platform also integrates innovative state-of-the-art retrieval agents, which can significantly improve the retrieval accuracy and outperform other agents in various scenarios.
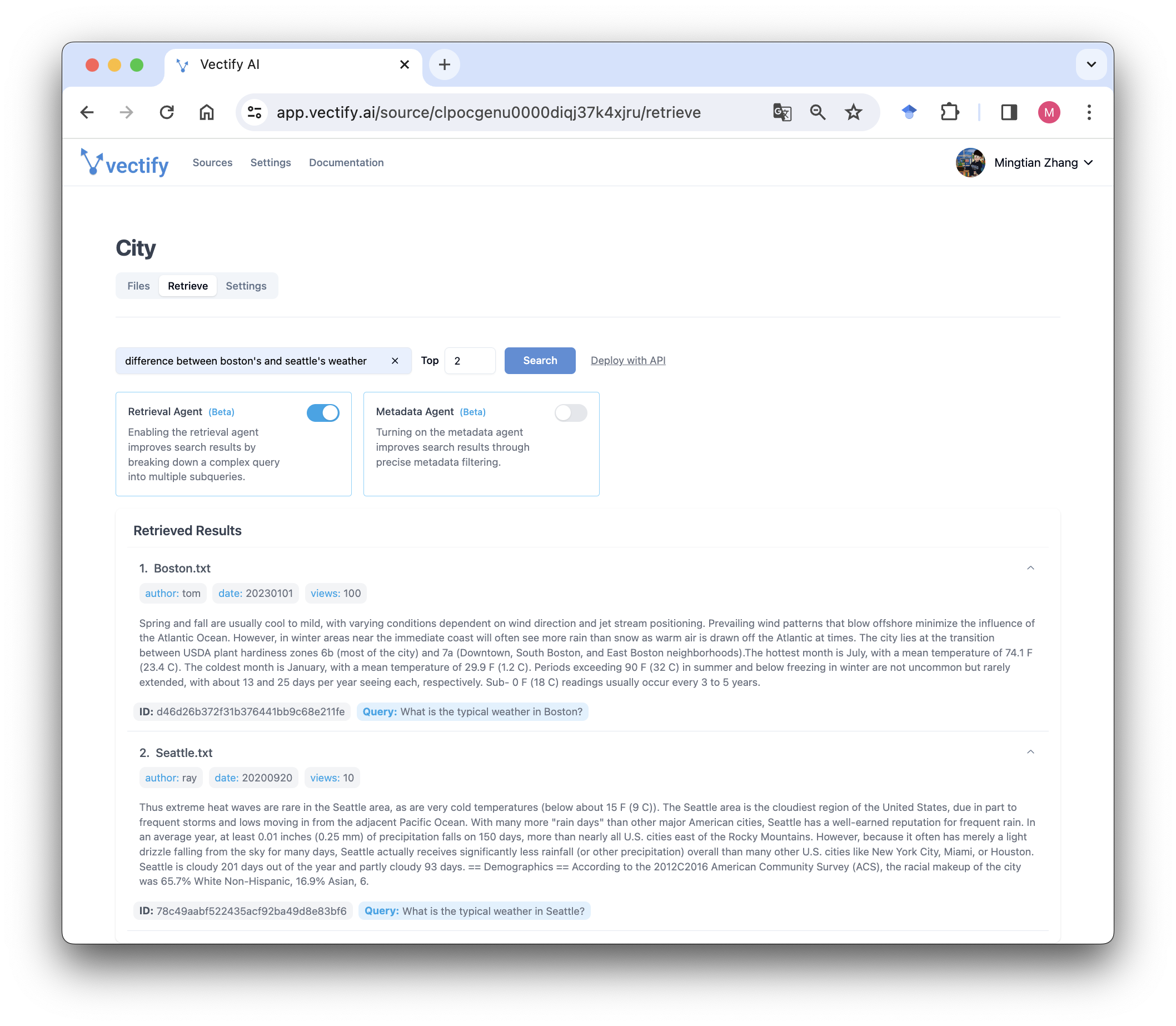
1. Multi-strategy Retrieval Agent with Reranking and Merging
Our retrieval API utilizes a multi-strategy retrieval agent, adept at complex queries with multiple objectives or multiple steps. This includes employing advanced techniques like query decomposition and Hypothetical Document Embeddings (HyDE). A standout feature of our approach, inspired by active learning, is the capability to effectively rerank and merge multiple retrieved lists into one list to return to the user. This re-rank and merge technique ensures a high recall rate with fewer top-K number. This means achieving more relevant results with less context tokens, optimizing efficiency and precision in information retrieval.
Multi-objective Query Example: What are the differences in gene therapy clinical trial regulations between the US and Europe?
Learn more on our Multi-strategy Retrieval Agent.
2. Metadata Agent for Hybrid Search
Traditional semantic-level approximate searches can often lead to irrelevant or redundant results, especially in scenarios where the results must meet specific conditions. For instance, if you're seeking documents from a certain time period or authored by a specific individual, semantic search may not be sufficiently precise.
To overcome this limitation, Vectify AI has developed a Semantic and Exact Hybrid Search, tailored for more precise and relevant outcomes. By integrating detailed document-level metadata, our retrieval service is capable of processing natural language queries with a nuanced blend of semantic understanding and exact metadata filtering. This not only refines the search results but also ensures they align precisely with your specified criteria, enhancing the overall effectiveness and efficiency of the retrieval process.
Hybrid Query Example: what are the FDA gene therapy regulations after 2021?
Learn more on our Metadata Agent.
Start Now For Free
We're excited to invite you to try out Vectify's RAG Platform for yourself. You can get started today for free and experience the future of retrieval technology. Unlock the power of RAG, hassle-free retrieval, and intelligent agents with Vectify AI. Contact us for integrating the cutting edge retrieval service into your API, database or other type of data sources, and discover how our service can elevate your generative AI applications.